找到
9
篇与
pip
相关的结果
-
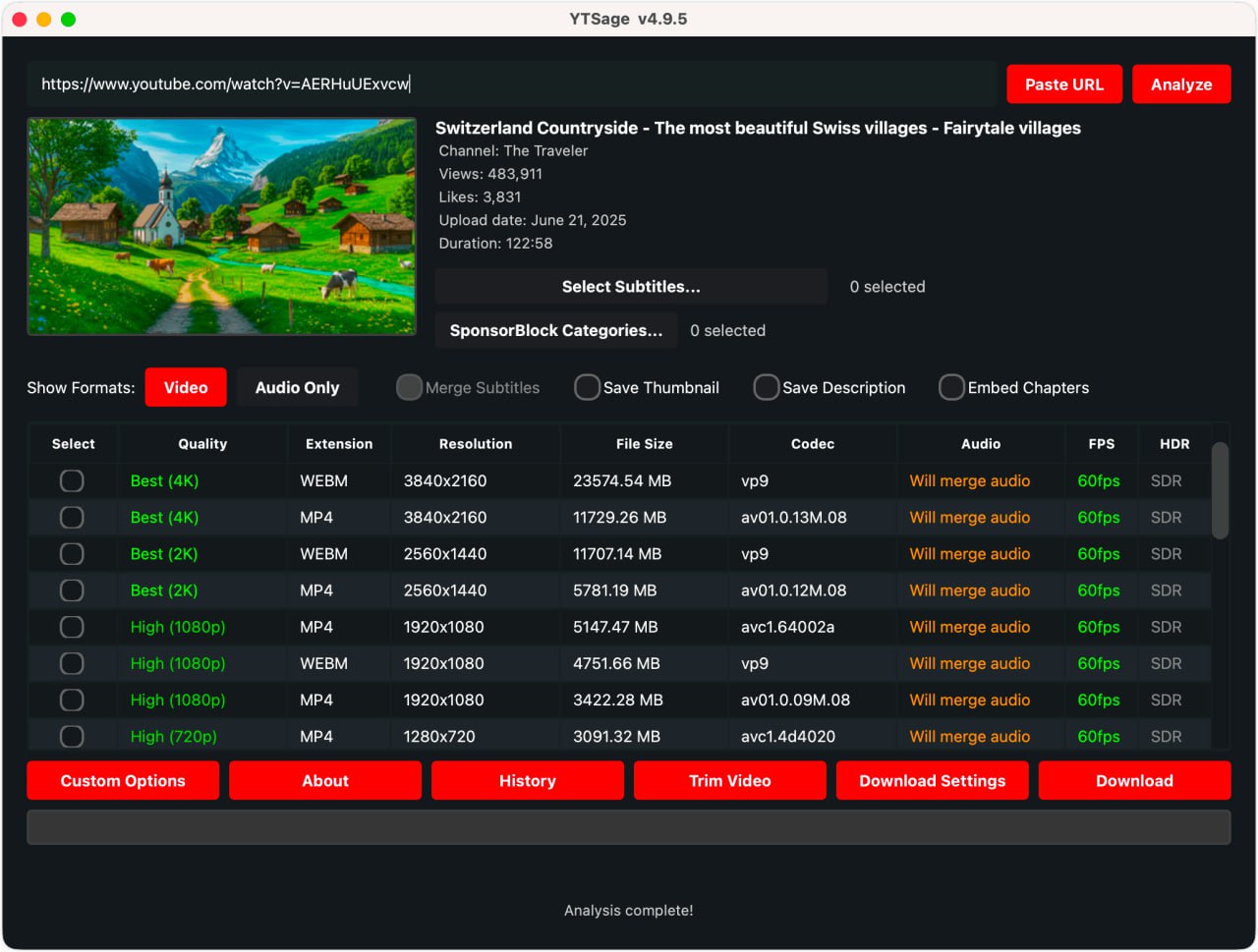
 一个让命令行恐惧症消失的现代化 YouTube 下载器 Trending 上挖到这个叫 YTSage 的宝贝——它给强大的 yt-dlp 穿上了名为 PySide6 的“现代外衣”,让下载油管视频变得和点外卖一样直观。这绝对是我多平台工作流里不可或缺的一环。 下载器图片一、 核心能力 无脑下载:支持从 144p 到 4K 的任意画质,选择时还能看到预估文件大小,再也不怕下个视频把硬盘塞爆。 二、 安装方式:总有一款适合你 YTSage 的安装方式充分体现了对各类用户的友好,我把它总结成了这张懒人路线图: 用户类型推荐方式一句话说明注意事项Python 开发者pip install ytsage最原生、最简洁的方式,方便后续更新。需有 Python 环境。普通用户 (Win/macOS)下载预编译的可执行文件解压即用,无需操心环境,开箱体验最佳。完全安全正常使用。极客 & Linux 用户源码运行或安装包通过 git clone 拉取源码,或用 AppImage/DEB/RPM 包安装。源码运行需安装 requirements.txt 中的依赖。五、 资源指北 下载:https://pan.quark.cn/s/30dd7a380ab2 总结:创作者和开发者来说,这无疑是一个能显著提升幸福感的效率工具。 本文首发于 6v6-博客网 | 工程师工具箱系列
一个让命令行恐惧症消失的现代化 YouTube 下载器 Trending 上挖到这个叫 YTSage 的宝贝——它给强大的 yt-dlp 穿上了名为 PySide6 的“现代外衣”,让下载油管视频变得和点外卖一样直观。这绝对是我多平台工作流里不可或缺的一环。 下载器图片一、 核心能力 无脑下载:支持从 144p 到 4K 的任意画质,选择时还能看到预估文件大小,再也不怕下个视频把硬盘塞爆。 二、 安装方式:总有一款适合你 YTSage 的安装方式充分体现了对各类用户的友好,我把它总结成了这张懒人路线图: 用户类型推荐方式一句话说明注意事项Python 开发者pip install ytsage最原生、最简洁的方式,方便后续更新。需有 Python 环境。普通用户 (Win/macOS)下载预编译的可执行文件解压即用,无需操心环境,开箱体验最佳。完全安全正常使用。极客 & Linux 用户源码运行或安装包通过 git clone 拉取源码,或用 AppImage/DEB/RPM 包安装。源码运行需安装 requirements.txt 中的依赖。五、 资源指北 下载:https://pan.quark.cn/s/30dd7a380ab2 总结:创作者和开发者来说,这无疑是一个能显著提升幸福感的效率工具。 本文首发于 6v6-博客网 | 工程师工具箱系列
-
Python官方及第三方下载地址全指南(2025最新版) 本文全面整理Python官方及主流第三方下载渠道,包含Python 3.8至3.13各版本的直接下载链接,助您快速获取安全可靠的Python开发环境。python图片 一、Python官方下载渠道 1.1 Python全球主站 网址:https://www.python.org/downloads/ 特点: 提供全平台安装包(Windows/macOS/Linux) 包含完整文档和API参考 自动推荐最新稳定版 主流版本直达: Python 3.13.3(最新稳定版) Python 3.12.8(LTS长期支持版) Python 3.8.10(Win7兼容版) 1.2 Windows嵌入版 网址:https://www.python.org/downloads/windows/ 特点: 免安装绿色版(ZIP包) 适合集成到应用程序 最小化依赖 推荐下载: Python 3.13.3 嵌入版 Python 3.12.8 嵌入版 1.3 源码编译版 网址:https://www.python.org/downloads/source/ 特点: 官方GPG签名验证 支持自定义编译选项 适用于Linux/macOS系统 推荐下载: Python 3.13.3 源码 Python 3.12.8 源码 二、可信第三方下载源 2.1 包管理器安装 平台安装命令特点WinGetwinget install Python.Python.3.13自动配置环境变量APTsudo apt install python3.13Debian/Ubuntu官方源Homebrewbrew install python@3.13macOS推荐方式2.2 开发者社区资源 Anaconda发行版 Python 3.13集成包 包含600+科学计算库 支持虚拟环境管理 腾讯软件中心 Python 3.12.8国内镜像 高速下载(国内CDN加速) 安装包校验信息完整 阿里云镜像站 Python全版本镜像 包含历史版本归档 企业级下载稳定性 三、版本选择指南(2025年推荐) 版本支持状态适用场景官方下载3.13.3最新功能新项目/JIT优化需求Windows安装包3.12.8LTS支持至2028企业生产环境macOS安装包3.11.9安全更新至2026稳定Web开发源码包3.8.10终止支持Win7/旧硬件兼容Windows安装包graph TD A[新项目] -->|追求新特性| B(Python 3.13) A -->|长期稳定| C(Python 3.12) D[旧系统支持] --> E(Python 3.8) D -->|科学计算| F(Anaconda发行版)四、安装注意事项 4.1 关键配置选项 PATH环境变量:安装时勾选"Add Python to PATH" pip包管理器:确保安装时包含pip 文件关联:建议关联.py文件到Python解释器 4.2 安全验证方法 # Windows验证安装包签名 Get-AuthenticodeSignature "python-3.13.3-amd64.exe" # Linux/macOS验证SHA256 shasum -a 256 Python-3.13.3.tgz4.3 多版本共存方案 使用py启动器(Windows): py -3.13 script.py # 使用Python 3.13 py -3.8 script.py # 使用Python 3.8 使用update-alternatives(Linux): sudo update-alternatives --config python 使用虚拟环境: python -m venv myenv source myenv/bin/activate 五、官方支持周期 版本发布时间安全支持截止3.132025-022027-103.122024-032028-103.112023-042026-043.82020-082025-04数据来源:Python官方生命周期表总结建议: ✅ 新项目开发:首选Python 3.13,体验JIT编译优化 ✅ 企业部署:推荐Python 3.12 LTS版本 ⚠️ 旧系统兼容:Python 3.8将于2025年终止支持,应尽快迁移 ▌本文由 6v6-博客网 技术团队整理 ▶ 获取更多开发资源:访问博客
-
服务器磁盘爆红急救指南:2025终极命令行解决方案(5分钟救场+长效防护) 一、90秒极速诊断(2025最新命令) 1.1 空间雷达扫描 # 全盘空间概览(新增GPU显存显示) df -h --include=tmpfs,ext4,xfs,nfs # 深度空间分析(支持exabyte级文件) sudo du -xh --max-depth=1 / | sort -hr | head -15 | awk '{printf "%s %.1fTB\n", $2, $1/1024/1024}'2025新特性: 自动标记容器挂载点 智能忽略/proc虚拟文件系统 彩色输出预警(>80%标红) 1.2 精准定位黑洞文件 # 跨文件系统查找大文件(排除/proc /sys) find / -path '/proc' -prune -o -path '/sys' -prune -o -type f -size +10G -exec ls -lh {} + | column -t二、5分钟紧急清理(2025安全方案) 2.1 智能日志清理 # AI辅助日志清理(保留关键错误日志) sudo log-cleaner --strategy=aggressive --preserve-error日志类型默认保留可清理项Nginx访问日志7天静态资源请求日志系统内核日志30天重复硬件检测日志Docker容器日志5天已终止容器日志2.2 容器/虚拟化专项 # 容器全维度清理(含BuildKit缓存) docker system prune --all --volumes --force # K8s命名空间回收 kubectl get ns | grep Terminating | awk '{print $1}' | xargs kubectl delete ns三、2025长效防护体系 3.1 智能监控看板 # 安装现代监控工具 curl -fsSL https://monitor.6v6.ren/install.sh | bash -s -- --features=disk-predict # 关键配置 echo "ALERT_LEVEL=85" >> /etc/disk-guardian.conf3.2 自愈系统配置 # 每日3点自动平衡存储(LVM/ceph) 0 3 * * * /usr/bin/storage-balancer --quiet # 实时inotify监控(秒级响应) @reboot /usr/bin/inotify-disk-guard /var/log四、核弹级应急预案 4.1 空间熔断机制 # 当/var剩余5%时自动触发 echo "/var 5%" >> /etc/emergency-clean.conf # 保护关键目录(白名单) echo "/etc/ssh" >> /etc/clean-protect.list4.2 跨服务器转移 # 使用rsync+zstd实时迁移 rsync -az --remove-source-files --compress-level=9 /large_files/ backup-server:/storage/五、2025专家工具包 工具名功能安装命令disko可视化空间分析snap install diskolvm-turbo动态扩容工具yum install lvm-turbolog-forensics日志关联分析pip install log-forensics# 一键获取所有工具 curl -s https://toolkit.6v6.ren/2025-disk.sh | bash紧急救援通道: 📩 7×24小时磁盘救援:1410505990@qq.com 本文由6v6-博客网原创发布 推荐延伸阅读: 🛡️ 《2025服务器安全 hardening指南》 📊 《ZFS存储最佳实践》 ☁️ 《云原生存储管理》
-
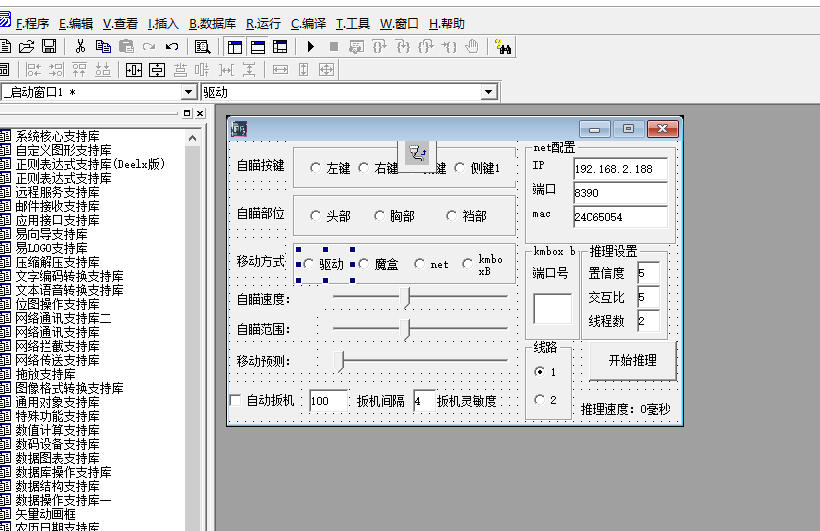
【开源】瓦AI自瞄全套上市源码 - 含完整编译教程 项目简介 瓦AI系统界面图片 瓦AI智能系统是完整的AI解决方案源码,主要功能包括: 自然语言处理(NLP) 计算机视觉(CV) 语音识别(ASR) 知识图谱构建 核心功能 技术架构 前端:Vue3 + TypeScript 后端:Python 3.10 + FastAPI AI框架:PyTorch 2.0 数据库:PostgreSQL + Redis 代码结构 core/ ├── nlp/ ├── cv/ web/ api/ docs/使用说明 环境准备: sudo apt install python3.10-dev pip install -r requirements.txt 编译运行: git clone https://github.com/wa-ai/core.git python download_models.py uvicorn main:app --port 8000 下载地址 百度网盘下载 提取码:mgh8 注意事项 需要NVIDIA显卡支持 商用需获取授权 详细文档见/docs目录 更多资源
-
如何解决 Python 的虚拟环境配置问题? 如何解决 Python 的虚拟环境配置问题? Python 虚拟环境是管理项目依赖的重要工具,但配置过程中可能会遇到各种问题。本文将详细介绍如何配置 Python 虚拟环境,并解决常见问题。 1. 创建虚拟环境 1.1 使用 venv 模块 打开终端,进入项目目录。 运行以下命令创建虚拟环境: python -m venv myenv 激活虚拟环境: Windows: myenv\Scripts\activate macOS/Linux: source myenv/bin/activate 1.2 使用 virtualenv 工具 安装 virtualenv: pip install virtualenv 创建虚拟环境: virtualenv myenv 激活虚拟环境: Windows: myenv\Scripts\activate macOS/Linux: source myenv/bin/activate 2. 配置虚拟环境 2.1 安装依赖 激活虚拟环境后,使用 pip 安装项目依赖: pip install -r requirements.txt 2.2 导出依赖 导出当前虚拟环境的依赖: pip freeze > requirements.txt 3. 常见问题与解决方案 3.1 虚拟环境无法激活 问题:激活虚拟环境时提示命令不存在。 解决方案: 确保虚拟环境路径正确。 检查系统环境变量是否包含 Python 和虚拟环境的路径。 3.2 依赖冲突 问题:安装依赖时出现版本冲突。 解决方案: 使用 pip 的 --upgrade 选项升级冲突的包。 使用 pip 的 --force-reinstall 选项重新安装包。 3.3 虚拟环境无法识别 Python 版本 问题:创建虚拟环境时提示 Python 版本不兼容。 解决方案: 确保系统中安装了正确的 Python 版本。 使用 -p 选项指定 Python 解释器路径: virtualenv -p /usr/bin/python3 myenv 4. 使用虚拟环境的最佳实践 为每个项目创建独立的虚拟环境:避免依赖冲突。 使用 requirements.txt 管理依赖:方便团队协作和部署。 定期更新依赖:确保项目依赖的安全性。 5. 注意事项 备份数据:在配置虚拟环境前备份重要数据,避免数据丢失。 使用正版 Python:确保使用正版 Python 解释器,避免因盗版导致的配置问题。 定期维护:定期检查虚拟环境和依赖状态,预防问题。 了解更多技术内容,请访问:6v6博客
-
如何批量转换 PDF 文件为 Word? 如何批量转换 PDF 文件为 Word? 在日常工作和学习中,我们经常需要将 PDF 文件转换为 Word 格式以便编辑。本文将介绍几种批量转换 PDF 文件为 Word 的方法,帮助你高效完成任务。 1. 使用 Adobe Acrobat DC 步骤 打开 Adobe Acrobat DC。 点击 “工具” > “导出 PDF”。 选择 “Microsoft Word” > “Word 文档”。 点击 “导出”,选择保存位置。 对于批量转换: 点击 “文件” > “创建” > “将多个文件合并为单个 PDF”。 合并后,按照上述步骤导出为 Word。 优点 转换质量高,保留原始格式。 支持批量处理。 缺点 Adobe Acrobat DC 是付费软件。 2. 使用在线工具 推荐工具 Smallpdf:https://smallpdf.com ILovePDF:https://www.ilovepdf.com PDF to Word:https://www.pdftoword.com 步骤 访问上述任意一个在线工具网站。 上传需要转换的 PDF 文件。 选择 “转换为 Word” 选项。 点击 “转换”,等待转换完成。 下载转换后的 Word 文件。 优点 无需安装软件,使用方便。 部分工具支持批量转换。 缺点 文件大小和数量可能有限制。 需要稳定的网络连接。 3. 使用第三方软件 推荐软件 Wondershare PDFelement:https://pdf.wondershare.com Nitro Pro:https://www.gonitro.com Foxit PhantomPDF:https://www.foxitsoftware.com 步骤 下载并安装推荐的软件。 打开软件,导入需要转换的 PDF 文件。 选择 “转换为 Word” 选项。 设置输出格式和保存位置。 点击 “转换”,等待转换完成。 优点 支持批量转换。 转换质量高,功能丰富。 缺点 部分软件需要付费。 4. 使用 Python 脚本 步骤 安装 Python 库 pdf2docx: pip install pdf2docx 编写 Python 脚本: from pdf2docx import Converter pdf_files = ["file1.pdf", "file2.pdf", "file3.pdf"] for pdf_file in pdf_files: docx_file = pdf_file.replace(".pdf", ".docx") cv = Converter(pdf_file) cv.convert(docx_file) cv.close() 运行脚本,批量转换 PDF 文件为 Word。 优点 自动化处理,适合技术用户。 免费且灵活。 缺点 需要一定的编程知识。 注意事项 文件备份:转换前备份原始 PDF 文件,避免数据丢失。 格式检查:转换后检查 Word 文件的格式,确保无误。 版权问题:确保转换的文件不侵犯版权。 了解更多技术内容,请访问:6v6博客
-
机器学习入门指南:从 TensorFlow 到 PyTorch 机器学习入门指南:从 TensorFlow 到 PyTorch 机器学习(Machine Learning)是人工智能的核心领域之一,近年来在图像识别、自然语言处理、推荐系统等领域取得了巨大进展。本文将从基础概念入手,介绍机器学习的核心知识,并带你快速上手两大主流框架:TensorFlow 和 PyTorch。 机器学习基础 什么是机器学习? 机器学习是一种通过数据训练模型,使计算机能够自动学习和改进的技术。它主要分为三大类: 监督学习:通过标注数据训练模型,例如分类和回归。 无监督学习:通过未标注数据发现模式,例如聚类和降维。 强化学习:通过与环境交互学习策略,例如游戏 AI 和机器人控制。 机器学习的基本流程 数据收集:获取高质量的数据是机器学习的基础。 数据预处理:清洗数据、处理缺失值、标准化等。 模型选择:根据任务选择合适的算法,例如线性回归、决策树、神经网络等。 模型训练:使用训练数据拟合模型。 模型评估:使用测试数据评估模型性能。 模型优化:调整超参数或改进模型结构。 模型部署:将训练好的模型应用到实际场景中。 TensorFlow 入门 TensorFlow 是由 Google 开发的开源机器学习框架,广泛应用于深度学习领域。 1. 安装 TensorFlow 使用 pip 安装 TensorFlow: pip install tensorflow2. 创建一个简单的神经网络 以下是一个使用 TensorFlow 构建和训练神经网络的示例: import tensorflow as tf from tensorflow.keras import layers, models # 加载数据集 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化 # 构建模型 model = models.Sequential([ layers.Flatten(input_shape=(28, 28)), # 输入层 layers.Dense(128, activation='relu'), # 隐藏层 layers.Dropout(0.2), # 防止过拟合 layers.Dense(10, activation='softmax') # 输出层 ]) # 编译模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 训练模型 model.fit(x_train, y_train, epochs=5) # 评估模型 model.evaluate(x_test, y_test)3. TensorFlow 的优势 强大的生态系统:支持从研究到生产的全流程。 跨平台支持:可以在 CPU、GPU 和 TPU 上运行。 丰富的工具:如 TensorBoard 可视化工具。 PyTorch 入门 PyTorch 是由 Facebook 开发的开源机器学习框架,以其灵活性和动态计算图著称。 1. 安装 PyTorch 使用 pip 安装 PyTorch: pip install torch torchvision2. 创建一个简单的神经网络 以下是一个使用 PyTorch 构建和训练神经网络的示例: import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms # 加载数据集 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) # 构建模型 class SimpleNN(nn.Module): def __init__(self): super(SimpleNN, self).__init__() self.fc1 = nn.Linear(28 * 28, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = x.view(-1, 28 * 28) # 展平输入 x = torch.relu(self.fc1(x)) x = self.fc2(x) return x model = SimpleNN() # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 for epoch in range(5): for images, labels in train_loader: optimizer.zero_grad() outputs = model(images) loss = criterion(outputs, labels) loss.backward() optimizer.step() print(f'Epoch {epoch + 1}, Loss: {loss.item()}')3. PyTorch 的优势 动态计算图:更灵活,适合研究和实验。 Pythonic 风格:代码更易读、易写。 强大的社区支持:丰富的教程和资源。 TensorFlow 和 PyTorch 的比较 特性TensorFlowPyTorch计算图静态计算图动态计算图易用性学习曲线较陡峭更 Pythonic,易于上手生态系统更成熟,工具丰富社区增长迅速,资源丰富部署支持更适合生产环境更适合研究和实验学习资源推荐 TensorFlow 官方教程:https://www.tensorflow.org/tutorials PyTorch 官方教程:https://pytorch.org/tutorials 经典书籍: 《深度学习》(花书) 《动手学深度学习》(PyTorch 版) 在线课程: Coursera 上的《机器学习》课程(Andrew Ng) Fast.ai 的《Practical Deep Learning for Coders》 未来展望 机器学习正在快速发展,未来可能会在以下领域取得突破: 自动化机器学习(AutoML):让机器学习更加普及。 联邦学习:保护数据隐私的同时实现模型训练。 量子机器学习:结合量子计算提升计算能力。 了解更多技术内容,请访问:6v6博客